2026
25 Million UK Property Rows in a Single Rust Process
Notes on perfect-postcode.co.uk. Every numeric feature is u16-quantised in a row-major array, so filter eval is two integer compares per row.
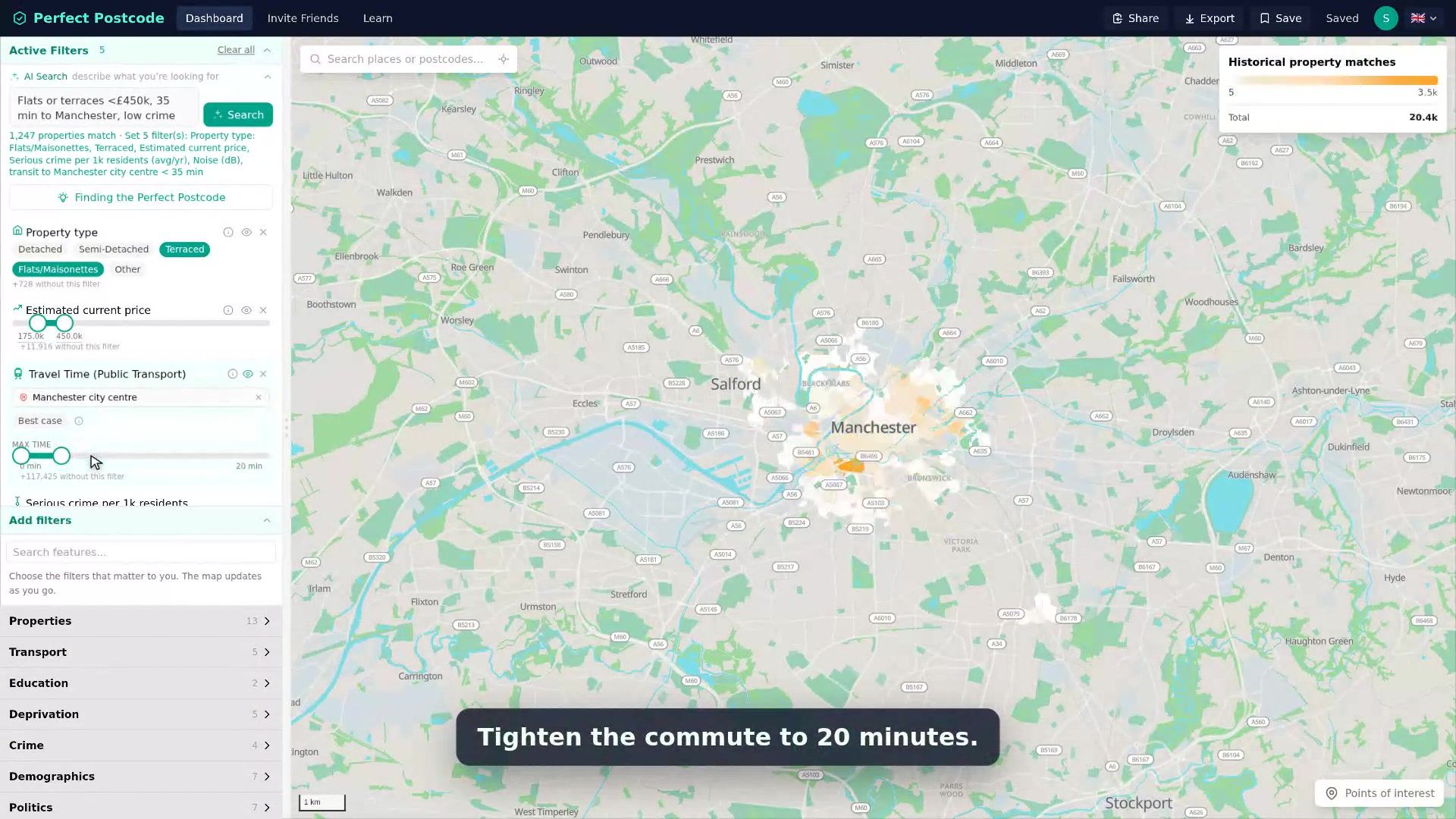
A user told me the map felt sluggish when they dragged it across Manchester with four filters on. They were right. The previous version round-tripped to a database, decoded floats, and lost the budget for a single pan inside the first filter. The rewrite is one Rust binary that holds the entire UK property history in RAM and treats every filter as three integer compares. Everything else in this post is the consequence of refusing to break that latency again.
The constraint that shapes everything
The answer to “what’s the median price in this hexagon, filtered to four-bedroom terraces under £450k with a 35-minute transit to Manchester” needs to come back inside a single map pan. Per visible cell, per request, every time the user moves anything. That’s the work.
At the resolution we want, the inputs are roughly 25M historical transactions, each with around 150 numeric features (price, EPC, deprivation deciles, school catchment metrics, POI proximities, noise, crime, …). Naively f32 per cell, that’s ~15 GB before you count anything else: postcodes, POIs, places, tiles, travel times. The rest of the architecture is the consequence of insisting it all lives in one process on one rentable box.
u16 quantisation in a row-major flat array
Every numeric feature is encoded as ((value - feature_min) / feature_range) * 65534. Dequant is raw * dequant_a + quant_min. u16::MAX is reserved as NAN_U16 (the explicit missing-value sentinel), so the live range is 65534, not 65535. Per feature we keep a (min, scale, p1, p99) tuple and a 100-bucket histogram for the UI sliders.
Storage is a single Vec<u16> laid out row-major: feature_data[row * num_features + feat_idx]. Sixteen features fit in one 64-byte cache line; a row scan stays in L1 for several rows at a time. With 25M rows × ~150 features × 2 bytes, the property matrix is around 7.5 GB, comfortably inside a 16 GB instance once the rest of the data joins it.
The precision loss is real but bounded: 0.01–0.1% per feature on the data we have, below the noise floor of any downstream statistic. The win is that the hot loop never touches an f32.
The hot loop is three integer compares
ParsedFilter carries min_u16 and max_u16: the user’s bounds requantised against the same per-feature (min, scale) at parse time. The row test is literal:
let raw = feature_data[base + filter.feat_idx];
raw != NAN_U16 && raw >= filter.min_u16 && raw <= filter.max_u16No string keys. No f32 decoding. Enum features go through a pre-built FxHashSet<u16> of allowed raw values, same shape.
Two small parse-time choices made this fast in practice:
- Sort filters by selectivity.
numeric.sort_unstable_by_key(|f| f.max_u16.saturating_sub(f.min_u16))puts the narrowest ranges first. A 50-filter request usually short-circuits on filter two or three. - Reject inverted ranges at parse time.
min > maxerrors out, sosaturating_subcan’t wrap a huge u16 into the sort key and silently reorder things.
Spatial: a CSR grid plus precomputed H3
Two indexes, used for different things.
A 0.01° (~1 km) regular grid in CSR layout (a single flat values: Vec<u32> of row indices and an offsets: Vec<u32> of per-cell starts) answers bbox queries. CSR avoids the 24-byte-per-cell Vec header you’d pay with Vec<Vec<u32>>, which is the difference between a few MB and a few hundred MB at UK scale. for_each_in_bounds is the variant that skips the result allocation; aggregators stream into it directly.
An H3 cell at resolution 12 is precomputed per property at boot, stored as Vec<u64>. Lower-resolution cells are derived via CellIndex::parent(); fast and exact. The hexagon endpoint thresholds at PARALLEL_THRESHOLD = 50_000: below, plain serial aggregation; above, rayon::par_chunks() with chunk = max(1000, rows / num_threads). Below the threshold, rayon’s per-chunk overhead dominates the work it’s parallelising; it’s worse than the obvious thing. Above, the slope flips.
A small per-thread FxHashMap<u64, u64> H3 cache inside each rayon chunk takes care of properties touched by multiple aggregations within the same chunk.
State is an Arc-clone away
AppState is large and immutable after the boot-time loads. SharedState = RwLock<Arc<AppState>> wraps it; every handler does shared.load_state(): a brief read lock, an Arc::clone, no further lock contention for the request.
The standard read-mostly pattern, but worth naming for one reason: it makes hot-reloading the parquet trivial later. Build a new AppState from disk, take the write lock, swap the Arc, drop the old one when the last in-flight request finishes. None of the handlers need to change.
On top of that there’s a per-endpoint ConcurrencyLimitLayer::new(N). The expensive endpoints (filter-counts, hexagon-stats, screenshot, export) get 3–5; the cheap ones get 20–30. It is the simplest backpressure you can write and it does most of the work.
PocketBase as the distributed lock
For mutations that need exclusion (subscription state transitions, redeem-invite races), there is no Redis. Instead, acquire_pocketbase_lock does an optimistic create against a locks collection. If create succeeds, we own it; if it fails on conflict, we fetch the existing lock, check expires_at_unix, and if it’s expired we delete and retry. Owner ID is a 24-char random string so stale-lock detection doesn’t rely on host identity or wall-clock skew.
Release is a Drop handler that spawns a tokio task to delete the record; async cleanup keeps the synchronous drop path free of I/O. 100 ms retry, 10-second acquire deadline. Coarse, but correct, audit-loggable in PocketBase, and adds zero new infrastructure to operate.
Cost-capping the LLM endpoint
The AI filter parser is a Gemini call. Two structural choices made it cheap enough to leave on:
- One system prompt, computed once.
build_system_prompt(features, mode_destinations)runs at boot. The feature catalogue, the enum of available travel modes, the few-shot examples: all concatenated once into aStringonAppState. Every request reuses the same bytes, which Gemini’s input cache likes. - A
search_destinationstool with a closed enum of modes. The LLM doesn’t get to invent place slugs. It can call the function; the server slugifies and resolves against the loaded travel-time directory using a word-overlap matcher tolerant ofkings-crossvsKing's Cross.
On top: a per-week token budget (AI_FILTERS_WEEKLY_TOKEN_LIMIT = 10_000_000) and a 2,000-token output cap. The budget is the actual cost guarantee; the per-call cap is belt-and-braces.
Smaller calls
mlockall(MCL_CURRENT | MCL_FUTURE)at startup. The hot dataset has to never page out. WithCAP_IPC_LOCKit works; without it we log and continue.malloc_trim(0)after each big load. Polars leaves a high allocator water-mark after parquet scans. Trimming after each major load gives back hundreds of MB of RSS before steady state.- Prometheus path normalisation.
/api/tiles/5/16/10becomes/api/tiles/:z/:x/:ybefore it becomes a label. Otherwise/.env,/wp-admin/..., and bot scans explode cardinality. - Median-half eviction over LRU. Token, share-bounds, and superuser-token caches evict the older half on overflow instead of one entry at a time. Cheap, and it spreads the re-validation cost instead of triggering a thundering herd.
spawn_blockingfor Polars I/O. Parquet scans are CPU-bound. They block the tokio executor if you let them; they don’t if you don’t.Box<[T]>instead ofVec<T>for aggregator accumulators. Nocapacityfield, 8 bytes saved per slot. At hundreds of hexagons × six features per request it adds up.- String interning, three times. Postcodes (~2.5M unique from 25M rows) live in a
lasso::RodeoReader; each row stores aSpur(~4 bytes). Address tokens are flattened into one buffer with per-row(offset, length)arrays. The same pattern for enum value strings. - Free-zone bbox check, not point check. Unlicensed queries must have their entire bbox inside
FREE_ZONE_BOUNDS. Point-in-zone would be convenient and wrong; it would let users pan to anywhere from a free-zone centre. - Share-link bounds are server-computed.
bounds_from_view(lat, lon, zoom)derives the bbox from a UK-aware longitude/latitude span (half_lat = half_lon * 0.6) and clamps it. Legacy short URLs without server-stored bounds grant nothing.
What I’d change
- Pin the allocator. I rely on
malloc_trimto keep RSS predictable. A jemalloc with explicit purge would behave better than glibc plus periodic trimming, especially under sustained load. - One bench for the hot loop. I trust the structure but I have no number for filter throughput per row per filter under typical load. That number would tell me when the u16 trick stops being enough.
- Move free-zone bounds to PocketBase.
FREE_ZONE_BOUNDSis aconst. It’s been right for the demo region for a year. The next time it changes I’ll regret hardcoding it. - A typed query DSL instead of
;;-separated strings. The current filter wire format isname:min:max;;name:val1|val2. Cheap to parse, awful to evolve. A small JSON envelope would survive the next feature.
There’s something a little embarrassing about a binary that just memory-maps a country. But the architecture made the latencies trivial, and the latencies are most of what a user feels.
Related articles
-
An Obsidian Sync Built Around the Merger I Already Had
VaultLink: self-hosted Obsidian sync. Edit in any editor, online or off, then come back to a converged vault. The app that justified reconcile-text.

-
A 3-Way Text Merger That Never Shows Conflict Markers
reconcile-text merges Markdown notes from three editors I don't control, with no history. Why git, CRDTs, and diff-match-patch each failed me.

-
Syncing State with an Immutable Trie
A visual goal tracker whose lasting idea was the sync model: an immutable trie so structural diffs are trivial and only deltas cross the wire.